������ȏ����W�����˙C�f���M�b�΄շ���
�r�g��2022��03��09�� �������Փ�� �Δ���
����ժҪ�����m���˙C�f���M�b�΄շ�����څ���s���΄սY���߾S���΄ՠ�B���g�������һ�N������ȏ����W�����˙C�f���M�b�΄շ��䷽�������ȣ����˙C�f���M�b�΄շ�����ʽ���鏊���W�����}���OӋ��ͨ�����D�M���΄շ���h����B�ı�ʾ����������ͨ�û��ĽM�b�J�P�Α�ģ�M�h������Σ����QDQN(DeepQNetworks)�㷨�l�����鹝�؆�����̽��Ч�ʵ��µĆ��}������˴�n�C�Ƽ�����M�㷨ArchiveDDQN(DoubleDQN)������B������ԓ�㷨�cģ�M�h���������M���˙C�f���M�b�΄շ�������̷��������ͨ�^�N��ͬ�y�ȵĽM�bģ�M�h���M�Ќ��Ȍ���C���������������Ч�ԡ�
�����P�I�~����ȏ����W��;��n�C��;�˙C�f��;�΄շ���;���a�M�b
����0����
������1990���ԁ�������I�е��˙C�f��(RC��Humanrobotcollaboration)�õ��ˏV�����о����Pע[14]�����I4.0�����У��˙C�f���ɞ�����I����Ҫ�ľW�j�������g�ʹٳɼ��g֮һ[5,6]�������˙C�f���Ĺ��I���Ô���Ѹ�����L7]�����У��M�b���˙C�f������Ȥ������ǰ���đ��È���֮һ8]�����˙C�f���M�b�Ĺ��I�OӋ�У��΄շ���Q�����˺͙C���˵Ĺ������ݺ͈���������Ӱ����˙C�f���������Ժ����aϵ�y��Ч�ʣ��Ǯ�ǰ�W���о��ğ��c֮һ�����y���˙C�f���M�b�΄շ��䷽��ͨ�������}��ʽ���鎧�s���ĽM�σ������}����ͨ�^�㷨�M�Ѓ����Ԍ��F�ض�Ŀ����������10��
����LAMON��11���΄Տ��s�ԡ��`���Ժ�������M��ָ�ˣ������һ�N�x�������㷨�����Ԍ��΄���ѵط���o������Ԫ�����ڽ��ٽY���ĸ���f���M�b���M������C��WANG��12�OӋ�˰����r�g���ĺ��˹��ąf���ɱ����������_�l�ˆ��lʽ�Є�Ӌ���㷨�����ɱ��������Ķ�������ĽM�b�΄շ��䷽����JOHANNSMEIER��13���˺͙C���˵IJ�������D�Ƶ���ͬ�ijɱ������У������ڷ������x��һ�N���lʽ�㷨�����˙C�f���M�b�ɱ���
������ɭ��14���YԴ���þ����ʡ����˲������s�Ⱦ����ʡ�ƽ���Q���^�̏��s�Ȟ�s���l��������С��ƽ����ӕr�g��Ŀ�ˣ���ʹ���z���㷨�����õ��˙C�f���M�b�΄շ�����ѷ��������y�ĽM�σ���������Ҫᘌ����ε��΄սY���͘OС���΄տ��g����δ���]�˺͙C���˾��Ɉ��еIJ�����ȱ���`���Ժ�ͨ���ԡ��S���˙C�f�����g�İlչ���M�b�΄յĽY����׃�����ӏ��s(���˙C���Ј��й����΄�)���΄տ��gҲ��������(��������˺Ͷ����C����)���ڳ�ֿ��]��Ҫ���˺͙C������Ϣ�Լ��M�b�s���l���£��˙C�f���M�b�΄շ��䌢���и߾S���s�Ġ�B���g���@�ǂ��y�ĽM�σ��������y�Խ�Q�ġ���������S�����W(IOT��InternetofThings)�İlչ����̎��������V��惦�cӋ��fͬ�{��15���Ƅ�߅��Ӌ��16�������ڌ��F����Ч�ʵĴ�Ҏģ�˙C�f���M�b�΄շ��䡣
����ֵ��ע����ǣ���ȌW���͏����W�����g��̎���߾S���s���g���}�ʹ�Ҏģ�Q�߆��}�ϱ��F�������@���ă��ݣ���˷����y�΄շ��䷽���ľ������ṩ���µķ�����ZHEYUAN��[17]�_�l��һ�N�µĻ�����ȈDע��W�j�ķ����㷨���ԄӌW�����䆖�}���������ڜyԇ�мs���΄շ��䆖�}�ҵ��˸��|�����΄շ��䷽������[18]ͨ�^���˙C�f���M�b�^�̸�ʽ�������ӳ��Ҏ�t���Α�Ҏ�t�ĽM�b��P����ʹ�û��ڏ����W�����������㷨���F�˿��{���߶ȵ��k�����M�b����������΄շ��䡣
�����S���ڽM�b��P�Ļ��A�ϣ���[19]���û�����ȏ����W���㷨DQN(DeepQNetworks)�Ķ������w�����W��MARLMultigenteinforcementearning��������΄շ�����ԣ���ͨ�^�M�b������C��ԓ�����ڲ�ͬ�΄Ք��������w���µ���Ч�ԡ��������о��Ć��l���Y���A�����R����ܰ�܇�����aϵ�y���Ŀ�����������һ�N������ȏ����W�����˙C�f���M�b�΄շ��䷽����
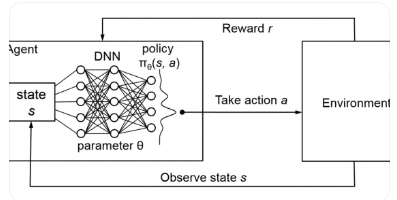
�����������Ȍ��˙C�f���M�b�΄��M�І��}��ģ���������J�P�Α���ʽ��ͨ�û������W�����h�����^�e���īI18]��19]�ĽM�b��P�������OӋ��ͨ�����D����ʾ�΄շ���ĭh����B���@�N��ʽ���H�ܸ������ط�ӳ�߾S���s�΄շ���h���Ġ�B��Ϣ�����ҿ���ֱ���D���锵�֏���ݔ�뵽����W�j�Ա�����ȏ����W���㷨����⡣��ԓ�M�b�J�P�Α�ģ�M�h���У�DQNϵ���㷨�����ڛ]���κ�ָ������r�ij�ʼ��B�_ʼ�����΄շ��������Ȼ������Ӗ���^���У��F�е�DQN�㷨���������e�`�����������l�����鹝�؆����ڌ��F�������΄շ���֮ǰ���㷨����������������ˣ������_�l�˴�n�C�ƣ��������㷨��̽��Ч�ʲ����ƽ��ػطŻ��ʡ�ͬ�r������߀�ṩ�˴�n�C�ƵăɷN����ģʽ������M�㷨ArchiveDDQN�����Mһ�������㷨�����ܣ����F����Ч���˙C�f���M�b�΄շ��䡣
����1.�˙C�f���M�b�΄շ��䆖�}��ģ
����1.1���}����
�����˙C�f�M�b���΄�ͨ��������������Ҫ���E�M�Ќ�ʩ���������΄շֽ⣬����һ���M�b�΄ղ�ֳ�һ�����������΄ա�������΄����������H������ͼs���Ȍ����΄հ���һ�����Ⱥ�����M�����С����Ҳ�����P�I�����΄շ��䣬��Ҫ�������΄��������M�й���ؓ�ɷ��䣬�Գ�ְl�]���˺ͅf���C���˵ĸ��ԃ��ݣ�������aЧ�ʡ����A�����R����ܰ�܇�����aϵ�y�@һ�Ŀ�У���Ҫ���Ŀǰ���Ԅ���������˙C�f���M�b�΄շ������У����˙C�f�����a��λ�Ŀ��ٲ��ú�Ҏ���ṩָ�������������������˙C�f���M�b�΄��^�̣�ʹ��ԓ�Ŀ��һ�Mǰ��ģ�K֧�ܵ��˙C�f���M�b�΄��M����ʾ��
����(1)�΄շֽ⡣ԓ�M�b�΄յ�Ŀ����ͨ�^ǰ������ϱ������˨�M(����˨�͉|Ƭ�M��)���B��֧�������ǰ���泯�ϕr���ȷ��Â���˨�M(B1~B4)��Ȼ��Q�o��˨������ͨ�^���Dʹ�ϱ��泯�ϣ����������cǰ����һ�¡�ԓ�΄ձ��ֽ��18�����΄գ������ʾ�������΄յ��������Ժ�����Ԫ�IJ������ԣ����΄տ��Է֞����N��ͣ��(�H�m����)���II(�H�m�ϙC����)���III(ͨ�����΄գ��m���˺͙C����)�����磬�˿����p�ɵ�ʰȡ��˨�M�ϣ������ʵ،���˨���뎧�ݼy�Ŀ��С�
�������ǣ��@���΄Ռ��ڙC���ˁ��f������Ҫ���M�dz��߰��Ĵ��r����Ƶģ�ʹ�ÙC���˔Q�o��˨�ٶȸ����ҿ��Ա��C�������A�o�������⣬��Щ�΄���ͨ�õģ��緭�D֧�ܛ]��̫�ߵļs��Ҫ����o�˺͙C���˶��ǿ��Եġ�ֵ��һ����ǣ��@�ͨ���͵��΄շ���o�˻��ߙC���˵Ĉ��Еr�g�����Dz�һ�ӵġ���ˣ��Ɍ��r�g헰�������Ԫ����M�Є��֡�
����(2)�΄������ڽM�b�΄գ������΄յĈ���������ܽM�b�l�����Ƶģ���aƷ�OӋ���|�����ơ������s���ȡ���ˣ���Щ���΄�֮�g�������s�������磬����ȷ�������˨�M�ϲſ���ȥ�Q�o���෴����Щ���΄�֮�g�]�����s�������ȷ����Ă���˨�M�ϡ����⣬������һ����˨�M�Ͼ��������ДQ�o����Ҳ�����S�ġ�����Ҏ���M�b����ڱ������У���ͬһ���������ϵ�������˨�M�Ϸ��ú�֮���و��ДQ�o���������������ر������΄�֮�g�����s�����OӋ���Pϵ�j��ꇡ����У���һ�к͵�һ�О����΄յľ�̖����̖
����(3)�΄շ��䡣һ����ԣ��΄������ܵ������Ɨl�����������ɵģ��@��ζ�����΄յľ��w���������ںܶ�����ԡ��@�o���������΄շ�����y�ȡ�ͬ�r���΄շ���߀Ҫ���]���΄յČ��Ժ�����Ԫ��ؓ�dƽ�⣬�Ԍ��F��Ĺ���Ч�ʡ����к���Ҫ��һ�c���ǛQ��ͨ�����΄յ�����o��߀�ǙC���˸����m��
����1.2��ʽ�������W��
�������˙C�f���M�b�΄շ�����ʽ����һ��ď����W�������Ԟ醖�}����ṩ�O��ı�����
����2�Դ�n�C�Ƹ��M���㷨ArchiveDDQN
����2.1��n�C�Ƽ���ԭ��
��������ȏ����W���㷨�У���MNIH��20,2�����DQN�㷨����̎���߾S�Ġ�B���g���}��չ�F����ă��ݡ��������DQN�õ��˘O��ĸ��M����չ[2���ڶ�NAtati�Α��ж�ȡ���˳�Խ���ƽ��ˮƽ�ijɿ������˙C�f���M�b�J�P�Α�h���У�DQNϵ���㷨���ԏ����_ʼͨ�^�����ԌW���@������΄շ�����ԏĶ�����J�P�Α���Ӗ���������A�Σ�����QN��Ƚ��ƾW�j��������ʼ�����S�C�Ժ���Ƚ��ƾW�j�M�������IJ��_���ԣ��㷨ʮ�����a���e�`�ķ�������������J�Pʧ���Ķ�ʹ�Α��鹝�l���؆����F���е��S���J�P�Α��O���˹����x��M�д�n���ڽK�Y������;�˳����Α����ͨ�^���d��n�^�m�M�С�
����2.2��n�C�Ƒ���ģʽ������M�㷨
����������n�C�Ƶ����c����������˃ɷN��n�C�Ƶđ���ģʽ���քe����ͨģʽ��n�C��(Archiveormalmode,Archive)��ͨ�Pģʽ��n�C��(rchiverushmod,Archive)�����˼�x����ͨģʽ������
�������⣬ͨ�Pģʽ��n�C��Archive�ܱ��C�������΄վ��ܵõ����䣬�������΄շ���ʧ����VANHASSELT����25���M��DoubleDQN(DDQN)�W���㷨��ͨ�^�ɂ��W�j�քe�M�ЌW����Q�ˌW���������ƫ�Ì��µĠ�Bֵ���^�ȹ�Ӌ�Ć��}����ˣ�������DQN�Ļ��A�ϣ�������Դ�n�C�Ƹ��M���㷨ArchiveDQN��
����3����ArchiveDDQN�M���΄շ���
����3.1ArchiveDDQN�㷨Ӗ���͜yԇ
�����ګ@ȡ�˙C�f���M�b�΄շ�����Ժ������֮ǰ����Ҫʹ���˙C�f���M�b�J�P�Α�ģ�M�h����ArchiveDDQN�㷨�������w�M��Ӗ���͜yԇ��
������Ӗ���^���У��M�b�J�P�Α�ģ�M�h����ArchiveDDQN�㷨֮�g��Ҫ�M�Ќ��r���������ȣ����Эh�����h����Bݔ�������D�Q�鏈��ݔ�뵽�㷨�Ľ��ƾW�j���㷨�����w�ó������������ģ�M�h�����з��������Ȼ��ݔ���µĭh����B�ͪ��Ȼ��ÿһ�Ϋ@�õķ���������h����B�ͪ����M�нyһ��ʽ�����뽛�ء����ͨ�^С�����S�C�ɘӳ�ȡ�����еĽ����������w�M��Ӗ�����Ķ�������M�����w���΄շ�����ԡ����M�Мyԇ�r����Ҫ�ȫ@ȡӖ���^�̵õ�����ȾW�j��������Ȼ����d����Ƚ��ƾW�j���cӖ���^�̲�ͬ���ǣ��yԇ�^�̲��M�н��طź�С�����ɘ�Ӗ���������w���΄շ�������ǹ̶���׃�ġ�
����3.2�@ȡ��΄շ�����Ժͷ��䷽��
����ͨ�^Ӗ���͜yԇ���ȣ����ԫ@������΄շ�����ԡ��ڑ���ArchiveDDQN�㷨�M���˙C�f���M�b�΄շ���r��ֻ�茢��΄շ�����Ԍ�������ȾW�j���������d���㷨����Ƚ��ƾW�j���ɡ�
�������΄շ����^���У��M�b�J�P�Α�ģ�M�h���cArchiveDDQN�㷨�nj��r�����ģ��挦�����ģ�M�h����B��ArchiveDDQN�㷨��������΄շ�������p�ɫ@����һ������΄շ���������@������չ���ӑB�΄շ�����ʮ�������ġ�ͨ�^����ģ�M�h�����㷨��ݔ����Ϣ���ɿ��٫@����΄շ��䷽�����M�b�J�P�Α�ģ�M�h���cArchiveDDQN�㷨֮�g�Ľ����ǰ��鹝���ֵģ�ͨ�^����һ�鹝�ķ�������������ɵõ�ԓ�鹝���΄շ��乤�����У��ɪ���ܶ��x��֪���۷e�������Ĺ������о�����̵Ĺ����r�L������΄շ��䷽����
����4����cӑՓ
����������C�΄շ���h���Լ���������M�㷨����Ч�ԣ��҂��ڃɂ���ͬ�y�ȵķ����΄��У���DQN�ʹ�n�C�Ƹ��M�㷨ArchiveDDQN(rchiveDQN��ArchiveRDQN)�M����Ӗ���͜yԇ������У����N�㷨��ʹ���īI[2�ṩ������W�j��ͨ�^�ɂ��W�j�քe�W��Ŀ�˺�����
����5�Y���Z
�������������һ�N������ȏ����W�����˙C�f���M�b�΄շ��䷽�������m���˙C�f���΄շ�����څ���s���΄սY���߾S���΄տ��g�����ĵ�ؕ�I�̈́����c��Ҫ�Ѓ��c��
����(1)���˙C�f���M�b�΄շ�����ʽ���鏊���W�����}����������ͨ�û��ĽM�b�J�P�Α�ģ�M�h����ʹ�ø߾S���s���΄շ��䆖�}���Ա�ݵ�ʹ����ȏ����W�������M�����;(2)����˴�n�C�Ƽ�����M�㷨ArchiveDDQN����Q�˂��yDQNϵ���㷨�鹝�l���؆��Ć��}���Mһ���������㷨�����ܺ��˙C�f���M�b�΄շ���ķ����ԡ��ڃɷN��ͬ�y�ȵČ��h���У���ͨģʽ��n�C�ƾ�����Ч����DQN�㷨��Ӗ���ٶȺ�Ӗ��Ч����
������ͨ�Pģʽ�£���n�C�Ƶõ��˸��õİl�]��ʹ��DQN�㷨�@���˃����ȫ��̽�������͜yԇ�����ԡ�����C������������˙C�f���M�b�΄շ��䷽������Ч�ԡ���δ���Ĺ����У������]�����s�Ĉ�����������M�b�΄յĻ�ψ��к�����О�IJ��_���Եȡ����Mһ����չ������㷨���I���õ�ͬ�r�������]���ø����M�ļ��gȥ�p��Ӌ����������Ӗ��Ч�ʡ�
���������īI��
����[1]ROBLAGOMEZS,BECERRAVM,LLATAJR,etal.Workingtogether:Areviewonsafehumanrobotcollaborationinindustrialenvironments[J].IEEEAccess,2017,5:2675426773.
����[2]WANGL,GAOR,VANCZAJ,etal.Symbiotichumanrobotcollaborativeassembly[J].CIRPAnnalsManufacturingTechnology,2019,68(2):701726.
����[3]ZACHARAKIA,KOSTAVELISI,GASTERATOSA,etal.Safetyboundsinhumanrobotinteraction:Asurvey[J].SafetyScience,2020,127:104667.
����[4]LIHao,LIUGen,WENXiaoyu,etal.Industrialsafetycontrolsystemandkeytechnologiesofdigitaltwinsystemorientedtohumanmachineinteraction[J].ComputerIntegratedManufacturingSystems,2021,27(2):16(inChinese).[���,����,��Ц���.�����˙C�����Ĕ��\��ϵ�y���I��ȫ�����wϵ�c�P�I���g[J].Ӌ��C��������ϵ�y,2021,27(2):16.]
����[5]SARA,JENSEN.TheIndustrialInternetofThings[J].OEMOffHighway,2016,34(7):2022.
�������ߣ���־�A1����2�����L��1������1�����ı�1,3,+�����2
- �n��˼�������У�����̜y�����n�̵Č��`�c˼��
- Ӣ�Z���I�̌W����ESP���¹����D���о�
- ���ڑ������˲����B�����ι��팣�I(������)���`�̌W�ĸ�
- �������ǽ̌W���Ļ��ʽ�n���OӋ�ԡ����ΌW��Փ������
- �F���W�gՓ�Ć��}���R��ָ�����о����ڌW�g�Wλ�͌��I�Wλ��Փ���x�}
- �Z�ČW�ƽ̎����������n���Ⱥ�����������Ҫ�̌Wԭ����ҕ��
- �����Ŀ���W����С�W���g���}��Ԫ�OӋ
- ���ڌWУ�Ļ����е�У���n�̽���
- �����Α�����������w��OӋ
SCI�ڿ�Ŀ�
���T�����ڿ�Ŀ�
SCIՓ��
- 2025-03-08һƪSCI/SSCIՓ�ď�Ͷ�嵽�����
- 2025-03-08SCIՓ��Ͷ���ʽҪ������Щ?����
- 2025-03-07Journal of Cleaner Production
SSCIՓ��
- 2025-02-28�������о����IӢ��Փ�Ŀ��x��
- 2025-02-19Cogent Education�ڿ��օ^��Ӱ�
- 2025-02-10���܌��I���ٰl��ssciՓ�ĵ�����
EIՓ��
- 2025-03-05EI���h���İlՓ�ģ����ָ��
- 2025-03-01EI���hՓ��ֵ�ðl��?2025EI���h
- 2025-02-28EI���hՓ���ڇ������Ă����e
SCOPUS
- 2025-02-07ʲô��ȫ���͔�����?scopus����
- 2025-01-24scopus�l�����¸�ʽ��ָ��
- 2024-11-19Scopus��䛵Ľ���������ڿ�
���g��ɫ
- 2024-11-22���H�����ڿ��l��Փ�đ�ԓ��ʲô
- 2024-11-22���H���Ľ̎����ڇ��H�����ڿ��l
- 2024-11-22���H�����ڿ��u�Q���J��
�ڿ�֪�R
- 2025-03-08�挦������ġ��ϴ���ġ�SCI��S
- 2025-03-072025�걱����ĵ�����Ŀ�����һ
- 2025-03-06�Ї�����ƌWͶ�����]��߀��Ͷ��
�l��ָ��
- 2025-03-07�����t�Y�ϡ��������P����Փ�ķ�
- 2025-03-07���x�����t�Y�ϡ��������P�����x
- 2025-03-06���@��ˎ��I�Ɍ���Փ���x�}